Stop Searching. Start Knowing. Why Every Knowledge Worker Needs a Personal Knowledge Operating System.
AI agents can execute tasks. Copilot can summarize documents. But nothing connects the dots across everything you know. I've been thinking about what's missing - and I think it's a Personal Knowledge Operating System.


Think about your typical Monday morning. You open your laptop. There are 47 unread emails. Three meeting invitations. A Slack message from your manager referencing a decision from two weeks ago that you vaguely remember. And somewhere in your OneDrive, there's a document with the numbers you need for today's steering committee. If only you could remember what it was called.
Sound familiar?
I've been living this reality for years as a knowledge worker. And lately, I've been thinking a lot about a fundamental problem that most of us share: we spend an insane amount of time searching for information instead of actually using it.
The real problem isn't the tools. It's the disconnect
We're not short on data. We have emails, meeting notes, calendars, documents, chat messages, voice memos. The information is there. But it lives in silos. Your email client doesn't know about your calendar. Your meeting notes don't connect to the contract you signed last quarter. And that voice memo you recorded after a client call? It's sitting in your phone, disconnected from everything else.
What we're really missing is the layer in between. Something that takes all these inputs and turns them into connected knowledge. Not just files. Not just search results. But actual context: "Here's what you need to know before this meeting. Here are the open actions. Here's what changed since last time."
I call this a Personal Knowledge Operating System.
What a Personal Knowledge Operating System actually looks like
The concept is straightforward, even if building it is not. Imagine a system with three layers:
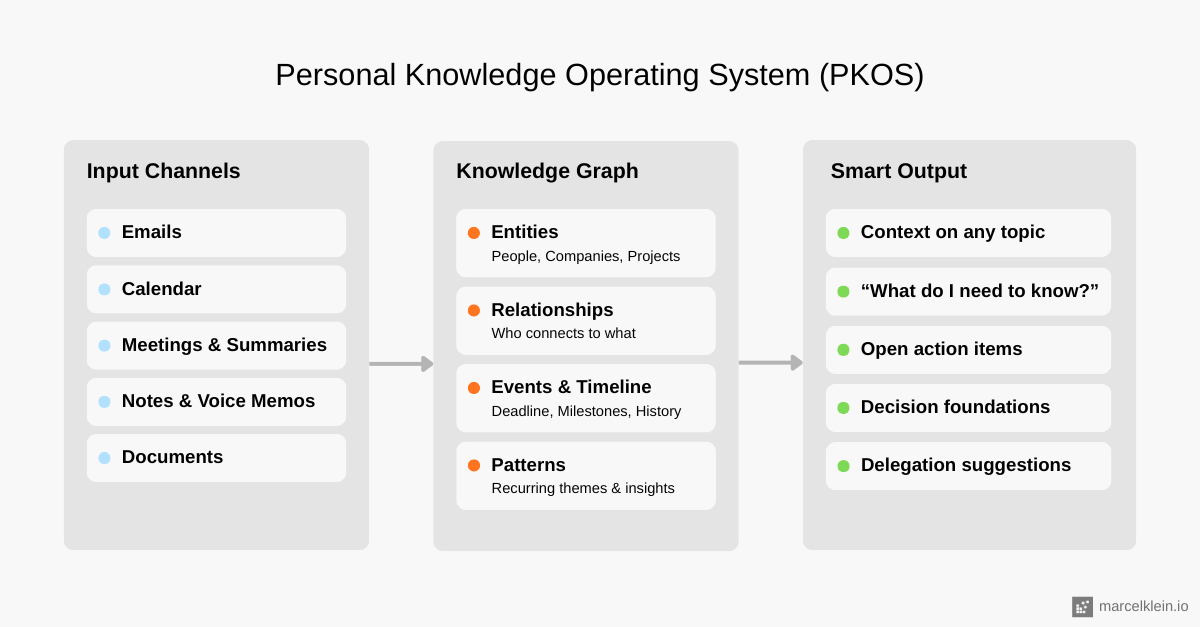
Input channels. All the places where information enters your work life. Meetings, emails, calendar events, documents, voice notes, chat messages. These are already there. You're already producing this data every single day.
A knowledge graph. And this is the crucial part. Not just a database of files, but a graph of entities and relationships. People, companies, projects, deadlines, amounts, decisions. Connected across documents and time. Your system knows that "Acme Corp" in last week's email is the same company mentioned in the contract from January and the meeting invite for next Thursday.
Smart outputs. Instead of you asking "where is that document?", the system tells you "Before your meeting with Acme Corp, here's what you need to know: there's an open invoice due in 3 days, the last status update mentioned a delay in Phase 2, and your colleague flagged a risk in the last project review."
That's the shift: from searching to knowing.
What Microsoft Copilot gets right. And where it stops
If you're working in the Microsoft 365 ecosystem, you've probably seen Copilot in action. And to be fair, it's impressive. Microsoft Graph connects your emails, Teams chats, calendar, SharePoint, and OneDrive. Copilot can summarize meetings, draft emails, and answer questions about your files.
But here's what I've noticed in practice: Copilot works within the M365 world. It can tell you what's in a document. It can summarize a meeting. But it doesn't build a persistent knowledge graph across all your interactions. It doesn't extract entities (people, companies, deadlines, amounts) and connect them over time. It doesn't do what I'd call temporal reasoning: "This invoice was issued 12 days ago with a 14-day payment term. It's due in 2 days."
And it certainly doesn't proactively push context to you before you even ask.
That's not a criticism of Microsoft. They're building in the right direction. But the gap between "AI-assisted search inside your files" and "a system that understands your professional world and acts on it" is still massive. is still massive.
The ecosystem is catching up. Slowly
What's interesting is that the building blocks to bridge this gap are starting to appear. MCP servers (Model Context Protocol) are creating a standardized way for AI models to interact with external tools and data sources. Workflow automation platforms like N8N already let you connect your email, calendar, CRM, and project management tools into intelligent pipelines.
And then there's OpenClaw. The open-source AI agent that went viral in a matter of weeks, collecting over 160,000 GitHub stars. If you haven't heard of it: OpenClaw runs locally on your machine or a dedicated VM, connects to your messaging apps, manages your inbox, schedules meetings, and executes multi-step tasks on your behalf. The hype got so real that Mac Minis actually sold out. People were buying dedicated hardware just to run their personal AI agent 24/7. People are calling it the closest thing to Jarvis we've seen. And honestly? The hype makes sense. It proves that people are hungry for AI that doesn't just talk, but actually does things across their tools.
But here's what I think the OpenClaw excitement also reveals: an agent is only as smart as the knowledge it can access. And that brings us back to the most fundamental truth about AI: it can only be as good and as relevant as the data we feed into it. OpenClaw is brilliant at executing tasks. It's the action layer. But it doesn't build a structured understanding of your professional world. It doesn't extract entities from your documents, detect relationships between people and projects, or create a persistent knowledge graph that grows over time. It acts, but it doesn't know.
So technically, the pieces of a Personal Knowledge Operating System are falling into place. MCP connects systems. N8N automates workflows. OpenClaw executes actions. But the knowledge layer, the part that truly understands your context and connects the dots across all your information, that's still largely missing for most knowledge workers.
Where Paperarchive fits into this picture
If you've heard of Paperarchive, you might know it as a simple idea: drop your documents in, and AI handles the rest. No manual tagging. No folder structures. You stop searching and start finding.
At its core, Paperarchive is a document processing engine. That's what it does really well. But documents are one of the richest input channels for any knowledge worker, and that makes them an ideal starting point for building something bigger.
Here's what's already working: when you upload a document to Paperarchive, AI analyzes it, extracts text via OCR, and makes it searchable through vector embeddings. You can ask natural questions and get answers. That's the foundation.
But I've already started going further. The system detects due dates and can highlight when something is overdue. It's not just storing your documents. It's beginning to understand them in the context of time.
The next layer I'm actively building is entity extraction. Every document contains valuable entities: company names, people, monetary amounts, dates, project references. Right now, most document management systems treat a PDF as a blob of text. Paperarchive is learning to pull out these entities and (this is the important part) connect them across documents.
That contract with Acme Corp? It's now linked to the invoice from the same company. And the meeting notes where their project was discussed. And the email thread about the delayed delivery. Not because you manually tagged them, but because the AI recognized the connections.
Why this matters for your day-to-day work
Let me paint a picture of what this looks like in practice.
You're a project manager. You walk into the office on Monday, and your system says:
"You have a meeting with Acme Corp at 2pm. Here's what's relevant: the last meeting was on January 15th, where you agreed on a revised timeline. Since then, an invoice for €45,000 was received. It's due this Wednesday. There's also a delivery note from last Friday that hasn't been confirmed yet. And your colleague Sarah added a note about a quality concern on January 22nd."
You didn't search for any of this. You didn't open five different tools. The knowledge graph connected the dots, and the system delivered what you needed. Proactively.
Or imagine you're preparing a decision. Instead of spending 45 minutes gathering data from different sources, your system presents the context: previous decisions on this topic, relevant financial data, stakeholder opinions from meeting notes, and open risks. That's not science fiction. That's entity extraction plus relationship mapping plus temporal awareness. And the building blocks exist today.
Where this is headed
I believe we're at a tipping point. The technology to build personal knowledge operating systems is here. Large language models for understanding content, vector databases for semantic search, graph databases for relationships, and speech-to-text for voice input. Tools like MCP and N8N are making it easier to connect the systems we already use.
But let me be honest about the scope. A true Personal Knowledge Operating System needs all your input channels: not just documents, but also emails, calendar events, meeting transcripts, chat messages, voice notes. Documents are only one piece of the puzzle, even if they're a particularly rich one.
What Paperarchive brings to the table is a strong starting point. It's where the document layer meets intelligence. Where a PDF stops being a blob of text and starts becoming connected knowledge with entities, relationships, and temporal awareness. That's the beginning of a knowledge graph, not the whole thing.
The full vision, a system that truly powers your workday by understanding your entire professional context, is still being built. By many people, across many tools. But the direction is clear: the future of knowledge work isn't about better search. It's about systems that understand your world and deliver the right information at the right moment, before you even ask.
And here's what excites me even more: this concept doesn't stop at knowledge workers. Think about a machine on a shop floor. Its "knowledge" is just as scattered. Maintenance logs in one system. Sensor data in another. Inspection reports in a folder somewhere. The warranty document nobody can find. A technician approaching that machine today has the same problem you have before your Monday morning meeting: no connected context. A Personal Knowledge Operating System for assets and machines would mean that before anyone touches a piece of equipment, the system surfaces what they need to know. Full history, open issues, related incidents, upcoming maintenance. That's a topic I'm thinking a lot about right now, and probably worth its own post. But the pattern is the same: scattered information becomes connected knowledge.
And with Paperarchive, I'm starting to build exactly that foundation. One document at a time.
Enjoyed the post or have feedback? I'd love to hear from you. Just reply via email, or connect on LinkedIn. Feel free to share this post on X, LinkedIn, or Facebook if you think someone else might enjoy it too.